Heart Disease ML: Predição de Doença Cardíaca
Heart Disease ML é um projeto de classificação que utiliza técnicas de Aprendizado de Máquina (Machine Learning) para prever a presença de doença cardíaca em pacientes, com base em características clínicas e exames.
O modelo vencedor, KNeighbors, alcançou uma acurácia de 82,07% no conjunto de testes.
🎯 Objetivo e Modelo Principal
Esta seção demonstra a aplicação de Machine Learning na predição de riscos na saúde.
Objetivo
O objetivo principal é prever a presença de doença cardíaca (target) com a maior precisão possível, avaliando o desempenho de diversos algoritmos de classificação.
Modelo Vencedor
Após a comparação, o KNeighbors foi selecionado como o modelo de melhor desempenho no conjunto de testes:
| Métrica | Valor |
|---|---|
| Acurácia Teste | 82.07% |
| Acurácia Treino | 90.28% |
💡 Tecnologias e Repositório
Aqui estão as ferramentas e bibliotecas utilizadas neste projeto e o link para o código completo.
⚙️ Tecnologias Principais
- Linguagem: Python
- Machine Learning: scikit-learn
- Processamento de Dados: Pandas & NumPy
- Visualização: Matplotlib & Seaborn
🌐 Repositório do Código
O código completo do projeto está disponível em:
⚙️ Funcionalidades e Pipeline
O projeto implementa um pipeline completo de Machine Learning, focado na classificação de risco.
Etapas do Pipeline
- Pré-processamento e Exploração de Dados com Pandas e NumPy.
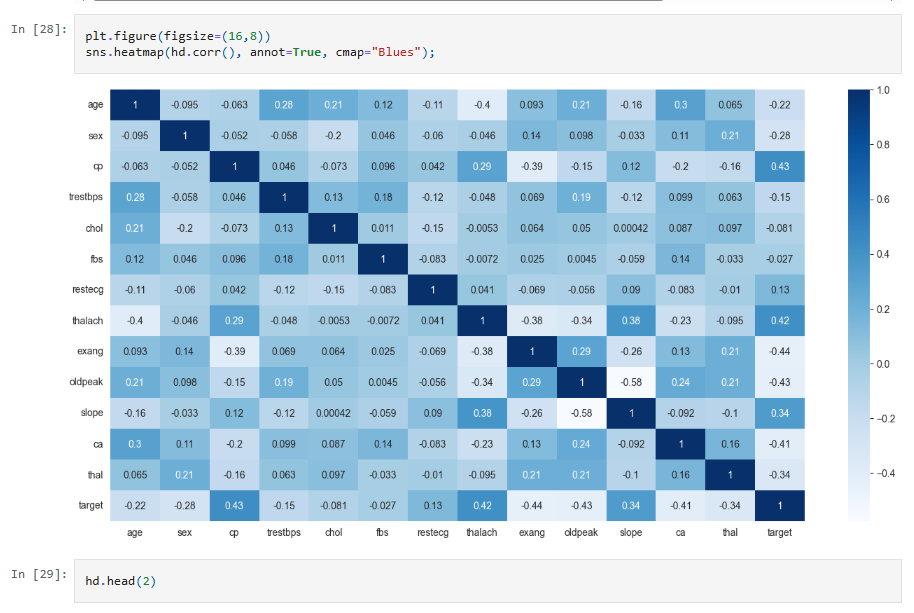
- Visualização de Dados para insights e correlações.
- Treinamento de Múltiplos Modelos de classificação (KNeighbors, Logistic Regression, Random Forest, etc.).
- Avaliação de Desempenho via Acurácia.
- Seleção do modelo de maior acurácia no teste.
📊 Resultados Detalhados dos Modelos
A tabela abaixo mostra o desempenho comparativo dos modelos avaliados.
| Modelo | Acurácia Treino (%) | Acurácia Teste (%) |
|---|---|---|
| KNeighbors | 90.28 | 82.07 |
| Logistic Regression | 91.67 | 81.38 |
| Random Forest Classifier | 100.00 | 79.31 |
| Ada Boost | 100.00 | 76.55 |
| Decision Tree | 100.00 | 67.59 |
📖 Variáveis do Dataset
As variáveis (features) utilizadas para a predição da variável alvo.
| Variável | Descrição |
|---|---|
| age | Idade da pessoa, em anos |
| sex | Sexo da pessoa (1 = masculino, 0 = feminino) |
| cp | Tipo de dor no peito (1 = angina típica a 4 = assintomático) |
| trestbps | Pressão arterial de repouso (mm Hg) |
| chol | Medida de colesterol (mg/dl) |
| fbs | Glicemia de jejum (> 120 mg/dl: 1 = verdadeiro, 0 = falso) |
| restecg | Eletrocardiograma em repouso (0 a 2) |
| thalach | Frequência cardíaca máxima atingida |
| exang | Angina induzida por exercício (1 = sim, 0 = não) |
| oldpeak | Depressão do segmento ST induzida por exercício |
| slope | Inclinação do segmento ST (1 = ascendente a 3 = descendente) |
| ca | Número de vasos principais (0–3) |
| thal | Talassemia (3 = normal, 6 = defeito fixo, 7 = defeito reversível) |
| target | Variável alvo: Presença de doença cardíaca (0 = Não, 1 = Sim) |